Transformer
What are the motivations for this work?
Recurrent Neural Network is the State-Of-the-Art approaches in NLP. And people want to improve its model quality and training efficiency (use more GPU for example).
The fundamental constraint of sequential computation limit its upper bound of performance.
What is the proposed solution?
Transformer eschewed recurrence (the part of sequential computation) and relied on attention mechanism, which allowed for significantly more parallelization.
Multi-head Attention
each of the layers in our encoder and decoder contains a fully connected feed-forward network 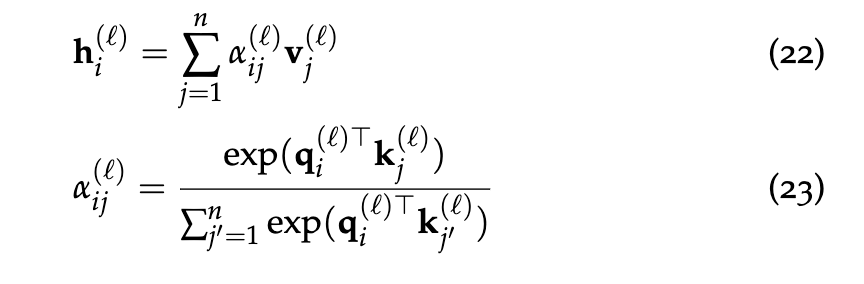 Lora is applies to
Lora is applies to
Position-wise Feed-Forward Networks
each of the layers in our encoder and decoder contains a fully connected feed-forward network
Related Knowledge
- RNN
- Long short-term memory (LSTM)
- Hidden State
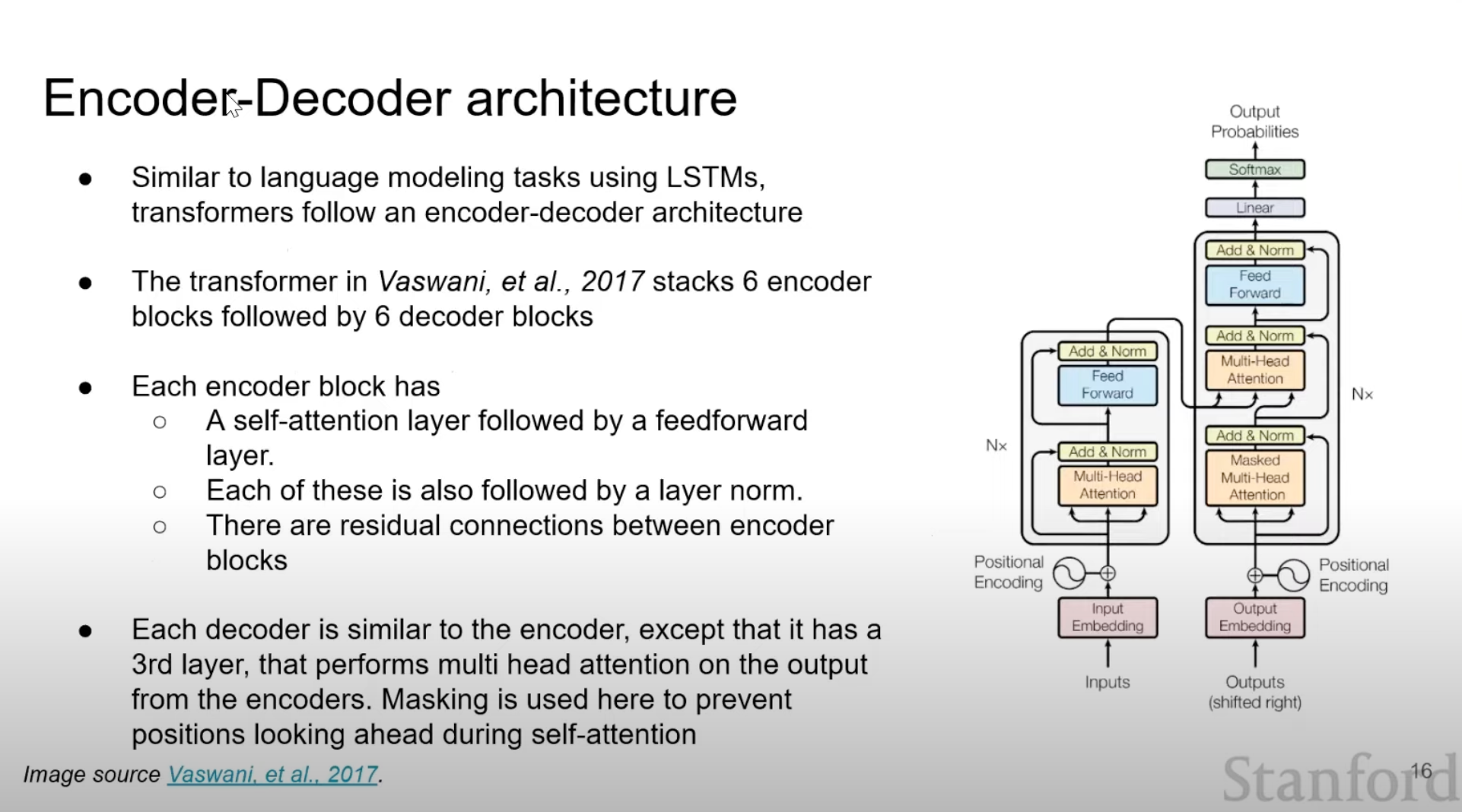
- Encoder-Decoder architecture
- Self-attention
- Attention, broadly construed, is a method for taking a query, and softly looking up information in a key-value store by picking the value(s) of the key(s) most like the query.
Useful Links
https://youtu.be/P127jhj-8-Y?si=ORJMt5Mam7pNxCQNhttps://web.stanford.edu/class/cs224n/readings/cs224n-self-attention-transformers-2023_draft.pdfhttps://zhuanlan.zhihu.com/p/604739354
 Canarypwn
Canarypwn