Tokenize, Vectorize and Embedding
What is token
 Token is more like translate human language to llm readable language use "vocabulary". In compilers, "Lexical tokenization is conversion of a text into (semantically or syntactically) meaningful lexical tokens belonging to categories defined by a "lexer" program", similar in LLM, LLM will tokeninze word into a "number" mostly depend on its "word class" or language properties.
Token is more like translate human language to llm readable language use "vocabulary". In compilers, "Lexical tokenization is conversion of a text into (semantically or syntactically) meaningful lexical tokens belonging to categories defined by a "lexer" program", similar in LLM, LLM will tokeninze word into a "number" mostly depend on its "word class" or language properties.
How to generate token
- Read tokenizer.py
- Load model. (So the tokenizer is different from each model, in this case,
llamauseSentencePiecefrom Google (Not from llama itself)) SentencePiece: A versatile subword tokenizer and detokenizer for neural text processing. SentencePiece is a language-independent subword tokenizer and detokenizer designed for neural text processing, including neural machine translation (NMT)
- Load model. (So the tokenizer is different from each model, in this case,
- Encode a string into a list of token IDs.
Cost
Try to run tokenizer for meta-llama/llama
My code is (modified from here)
from llama import Tokenizer
model_path = 'tokenizer.model'
tokenizer = Tokenizer(model_path=model_path)
text = "What is the answer to the life, the universe and everthing?"
tokens = tokenizer.encode(text, bos=True, eos=False)
print(tokens)
for tid in tokens:
tk = tokenizer.decode([tid])
print(f"{tid:>6} -> '{tk}'")
print(tokenizer.decode(tokens))Result:
[1, 1724, 338, 278, 1234, 304, 278, 2834, 29892, 278, 19859, 322, 3926, 1918, 29973]
1 -> ''
What is the answer to the life, the universe and everthing?
1724 -> 'What'
What is the answer to the life, the universe and everthing?
338 -> 'is'
What is the answer to the life, the universe and everthing?
278 -> 'the'
What is the answer to the life, the universe and everthing?
1234 -> 'answer'
What is the answer to the life, the universe and everthing?
304 -> 'to'
What is the answer to the life, the universe and everthing?
278 -> 'the'
What is the answer to the life, the universe and everthing?
2834 -> 'life'
What is the answer to the life, the universe and everthing?
29892 -> ','
What is the answer to the life, the universe and everthing?
278 -> 'the'
What is the answer to the life, the universe and everthing?
19859 -> 'universe'
What is the answer to the life, the universe and everthing?
322 -> 'and'
What is the answer to the life, the universe and everthing?
3926 -> 'ever'
What is the answer to the life, the universe and everthing?
1918 -> 'thing'
What is the answer to the life, the universe and everthing?
29973 -> '?'
What is the answer to the life, the universe and everthing?It runs on cpu, cost 200MB memory and 20% of 16 core CPU (paralleled).
What is Vectorize
A vector is a single-dimensional array of tokens.
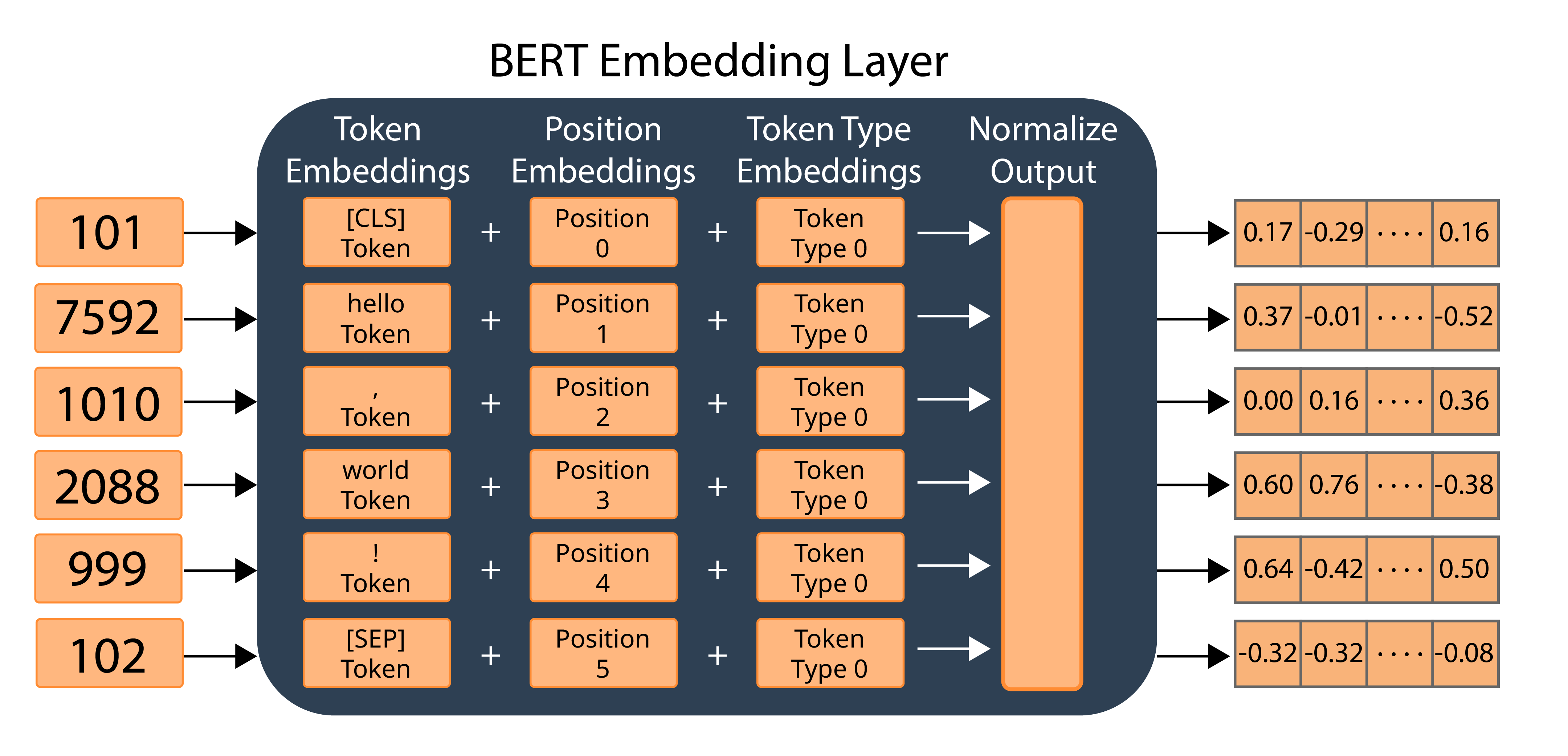
Embedding
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)Output:
[[ 0.0225026 -0.07829173 -0.02303073 ... -0.00827929 0.02652686
-0.00201898]
[ 0.04170233 0.00109741 -0.0155342 ... -0.02181629 -0.0635936
-0.00875287]]Embedding is "Encoded" result of tokens and vectors processed by Transformer models. It not only contains the information of "input words", but also information of "sentences".
It cost 662 MB of GPU Memory.
Conclusion
- All embeddings are vectors, but not all vectors are embeddings.
- Token is the basic unit.
- LLMs take embeddings.
References
- https://thenewstack.io/the-building-blocks-of-llms-vectors-tokens-and-embeddings/#:~:text=Embeddings are what allow LLMs,its relationships with other tokens.
- https://medium.com/@liusimao8/using-llama-2-models-for-text-embedding-with-langchain-79183350593d
 Canarypwn
Canarypwn